Keywords are at the heart of any SEO strategy. They are the thread that links sites to customers via their search terms. Over the years, people have focused and speculated a huge amount about how precisely to use keywords in on-page content to signal relevance to search engines and to rank well.
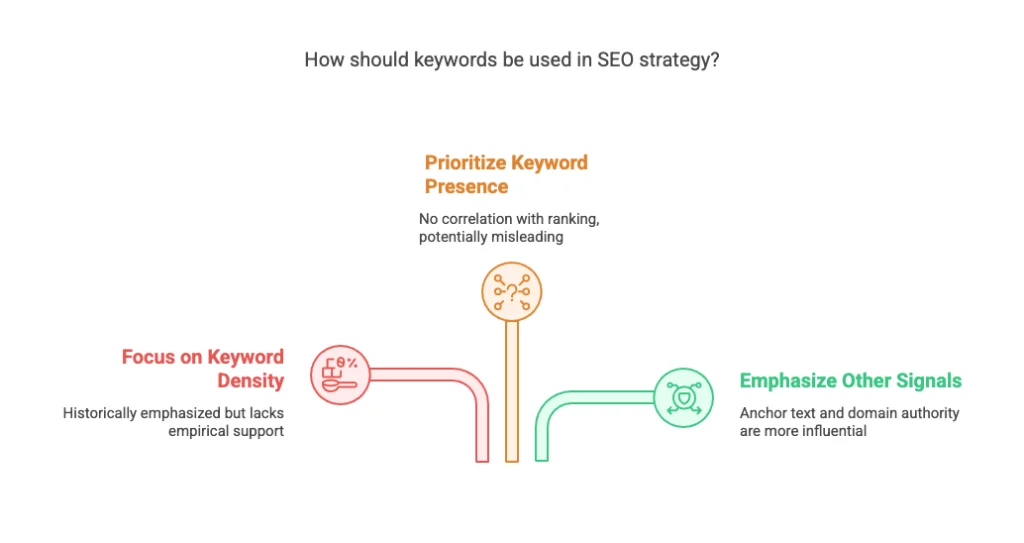
Historically, people have talked about keywords a lot, often focusing on minute details like “how many angels can dance on the head of a pin”: where to place them in the content, how many words should separate them from the start of a page or heading, the ideal ratio of keywords to other text, and so on.
Some (not very good) SEOs strive to produce content that contains an exact percentage of keywords, often with the result of producing content that isn’t very readable to humans. And some stick to the old tactic of writing as many pages as possible stuffed with keyword variants and synonyms to cover all possible long-tail searches.
Not much has been done
Empirically verify these speculations and strategies until recently. Mark Collier over at The Open Algorithm is at least attempting to do something about that.
He has embarked on a program of testing purported signals to see how well they correlate with rankings, including collecting keyword density measurements for over a million pages and over 12000 keywords. Using a mathematical technique for measuring correlation (Spearman’s Correlation co-efficient), the results showed no positive correlation between keyword density and SERP position, and even a slight negative correlation. We won’t go deeply into his methods here — or its flaws, but you can read about both at The Open Algorithm.
This result shouldn’t surprise anyone working in SEO today. However, the data leads to another conclusion. This conclusion should definitely make people pause and think. In another test, Collier examined whether the presence of a keyword on a page was correlated with ranking. The results showed no correlation at all. That is, these tests show that a page’s ranking for a keyword doesn’t correlate with whether the page contains that keyword in its text.
How can that be?
Indexing for a keyword differs from ranking highly for it. Having specific keywords on a page might link it to that keyword in the index. However, it seems to have no effect on the page’s position in the SERPs. It’s likely Google influences results more with other signals. Collier’s results support this. These signals include anchor text and domain authority of incoming links. They also include the page title and meta tags.
So, should we stop caring about keywords. Absolutely not. Collier’s methodology might face criticism. You can see comments on his articles. Nevertheless, his results should spark an interesting discussion in the SEO world. This discussion should focus on incorrect ideas. Hopefully, his work will encourage others. They might then apply a more rigorous approach to search engine optimization. This approach should be mathematical and scientific.
What do you think. Is Collier on to something, or is his method so flawed that his results can be disregarded. Does your experience contradict his results. Let us know in the comments.



